
SQLDF
Aprenda a trabalhar com duas ferramentas ao mesmo tempo, podemos trabalhar com SQL dentro do RStudio.
![]()
Em estatística, a análise exploratória de dados (AED) é uma abordagem à análise de conjuntos de dados de modo a resumir suas características principais, frequentemente com métodos visuais. Um modelo estatístico pode ou não ser usado, mas primeiramente a AED tem como objetivo observar o que os dados podem nos dizer além da modelagem formal ou do processo de teste de hipóteses. A análise exploratória de dados foi promovida pelo estatístico norte-americano John Tukey, que incentivava os estatísticos a explorar os dados e possivelmente formular hipóteses que poderiam levar a novas coletas de dados e experimentos. A AED é diferente da análise inicial de dados (AID), que se concentra mais estreitamente em verificar os pressupostos exigidos para ajuste de modelos e teste de hipóteses, além de manusear valores faltantes e fazer transformações de variáveis conforme necessário. A análise exploratória de dados abrange a AID.
A análise exploratória de dados emprega grande variedade de técnicas gráficas e quantitativas, visando maximizar a obtenção de informações ocultas na sua estrutura, descobrir variáveis importantes em suas tendências, detectar comportamentos anômalos do fenômeno, testar se são válidas as hipóteses assumidas, escolher modelos e determinar o número ótimo de variáveis.
Esse estudo estará utilização dados coletados e tratados pelo Kaggles, o qual disponibilizou esse dataset neste link. Com base nas informações dispostas nesse dataset, realizarei Insights acerca dos tripulantes e das circunstâncias que envolveram a tragédia. Vale lembrar que tal conjunto de dados não abriga informações de todos os passageiros, mas sim de apenas 891.
 Nesse projete iremos analisar uma série temporal de uma empresa de locação de
bicicleta dos Estados. Unidos. O conjunto de dados é obtido na plataforma Kaggle. Nesse
conjunto de dados, iremos realizar uma análise exploratória em relação da demanda de locação
de bicicleta dos dias da semana, dia úteis, com dias de finais de semanas e feriados, qual a
correlação de locação de bicicleta com a temperatura e humidade do ar, se a velocidade do
vento interfere em relação a damanda de locação. Toda este projeto foi desenvolvido em
linguagem R.
Nesse projete iremos analisar uma série temporal de uma empresa de locação de
bicicleta dos Estados. Unidos. O conjunto de dados é obtido na plataforma Kaggle. Nesse
conjunto de dados, iremos realizar uma análise exploratória em relação da demanda de locação
de bicicleta dos dias da semana, dia úteis, com dias de finais de semanas e feriados, qual a
correlação de locação de bicicleta com a temperatura e humidade do ar, se a velocidade do
vento interfere em relação a damanda de locação. Toda este projeto foi desenvolvido em
linguagem R.
Iremos utilizar a função read.csv().Abaixo demonstraremos como carregar um conjunto de dados,
lembrando que é preciso determinar alguns parâmetros, file ou path, caminho do diretório do arquivo
em seu computador, header indica se o conjunto de dados tem ou não o nome das variáveis e como é um arquivo
csv temos que demonstrar qual é o separador, nesse dataset é a vírgula.
Abaixo temos 02 exemplo, o primeiro,
baixar o arquivo, e salva em seu computador. Ou Caso preferir pode
utilizar a segunda opção que pega o arquivo direto do repositório do GitHub.
# Primeira Opção
df <- read.csv(file = 'C:/Users/Downloads/data_titanitc.csv')Ou
# Segunda Opção
df <- read.csv(file = 'https://raw.githubusercontent.com/rodolffoterra/rodolffoterra.github.io/main/dados/data_titanic.csv')
head(df)| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarket |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22 | 1 | 0 | A/5 21171 | 7.2500 | s | |
| 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Thayer) | female | 38 | 1 | 0 | pc 17599 | 71.2833 | c85 | c |
| 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26 | 0 | 0 | STON/O2. 310128 | 7.9250 | s | |
| 4 | 1 | 1 | Futrelle, Mrs. Jacques Heath (Lily May Peel) | female | 35 | 1 | 0 | 113803 | 53.1000 | c123 | s |
| 5 | 0 | 3 | Allen, Mr. William Henry | male | 35 | 0 | 0 | 373450 | 8.0500 | s |
Acima você pode conferir as primeiras e últimas linhas do dataset. As informações podem causar certa confusão no primeiro momento, portanto, vamos esclarecer alguns pontos sobre eles, a começar pela remoção de colunas que não usaremos, como a “PassengerId”, “Ticket” e “Cabin”, que contém informações sobre o código de identidade do passIdadeiro, o número da sua cabine e do seu bilhete, respectivamente. Acredito que essas informações não são pertinentes ao estudo que faremos e sua permanência poderia causar perda de foco.
df <- df[,-c(1,9,11)]Caso a função acima possa parecer estranho, leia o material anterior: Data Frame.
Com as colunas removidas em nosso conjutno de dados, iremos renomear as colunas remanescentes.
colnames(df) <- c("Sobrevivente", "Classe","Nome","Sexo","Idade","Irmãos/Cônjuge","Pais/Crianças","Tarifa","Embarque")
Com as colunas devidamente renomeadas para um melhor entendimento, é hora de explicarmos o que cada um desses dados significa. Acompanhe abaixo cada coluna com seu respectivo significado:
A função abaixo mostra a quantidade de linhas (Observações), quantidade de colunas (variáveis) o nome, o tipo da variável que foi classificado pelo RStudio cada variável e a composição das variáveis.
str(df)
glimpse(df)
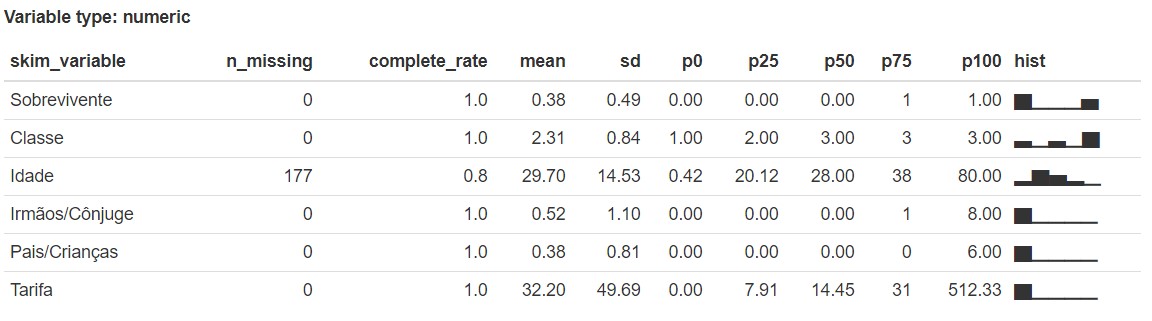
Já a função skim(df) mostra com maiores detalhes cada variáveis, começamos a ter uma ideia de como
cada informação está organizada em nosso conjunto de dados.
skimr::skim(df)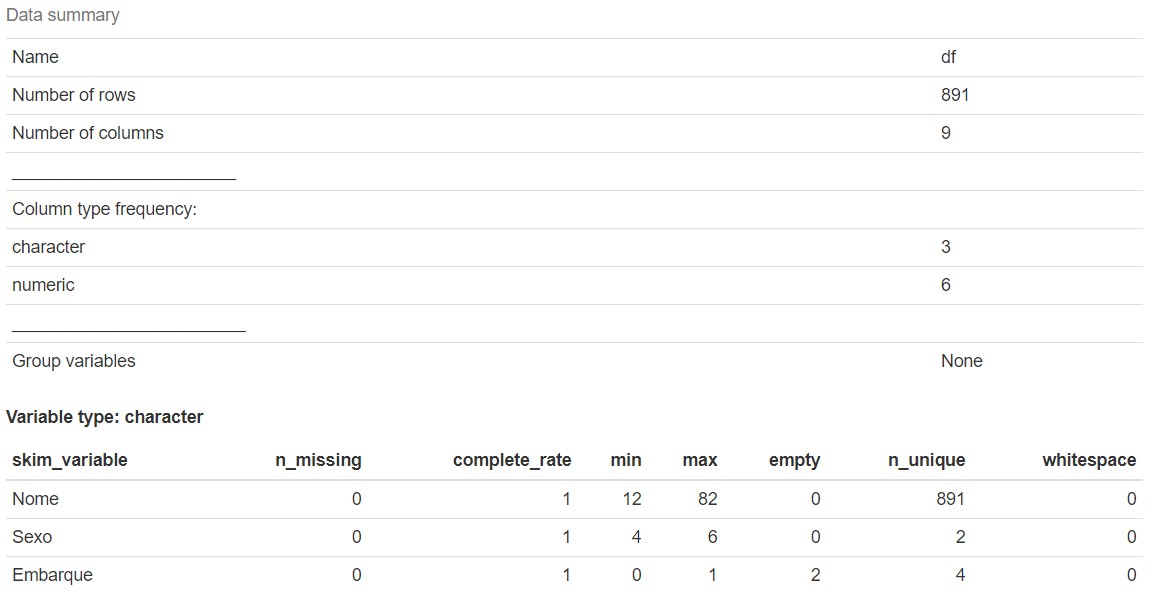
Abaixo estamos querendo saber quais variáveis foram classificados como numéricas pelo próprio RStudio
colunas_numericas <- sapply(df, is.numeric)
colunas_numericas
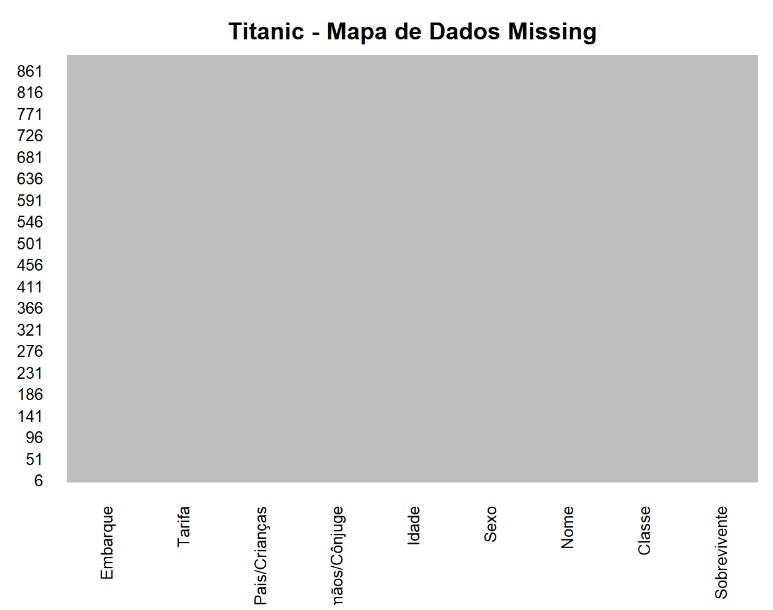
missmap(df,
main = "Titanic - Mapa de Dados Missing",
col = c("black", "grey"),
legend = FALSE)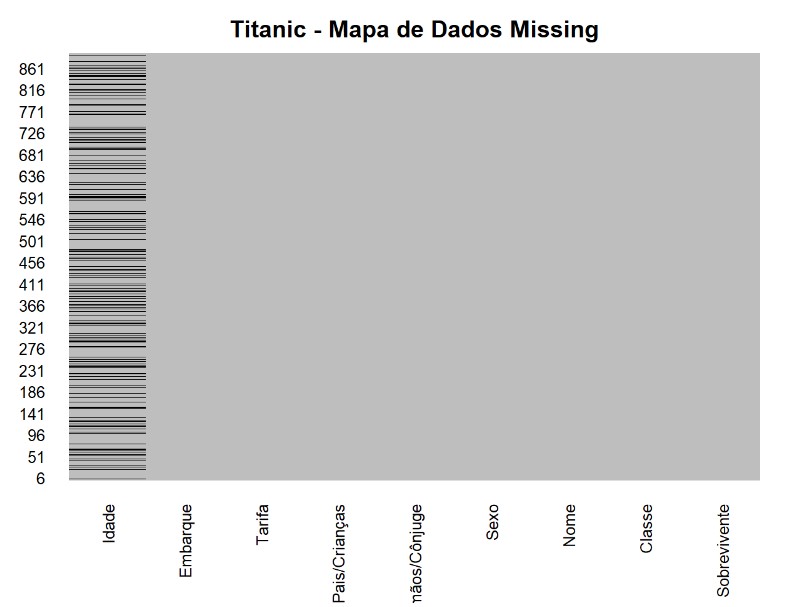
Podemos saber a quantidade de número missing por variável.
sapply(df, function(x) sum(is.na(x)))
Observar que a coluna idade possui muitos valores missing. Precisamos remover incluir valores no lugares desses espaços vazios. Para isto decidimos realizar a seguinte técnica. O grafico abaixo mostra um boxplot da faixa etária por classe.
df$Classe <- factor(df$Classe, labels = c("1ª Classe", "2ª Classe", "3ª Classe"))
ggplot(df, aes(Classe, Idade)) +
geom_boxplot(aes(group = Classe, fill = Classe), alpha = 0.4, show.legend = FALSE) +
scale_y_continuous(breaks = seq(min(0), max(80), by = 10)) +
theme_classic() +
labs(title = "Quantidade de Pessoas por Classe",
y = "Idade",
x = "Classe")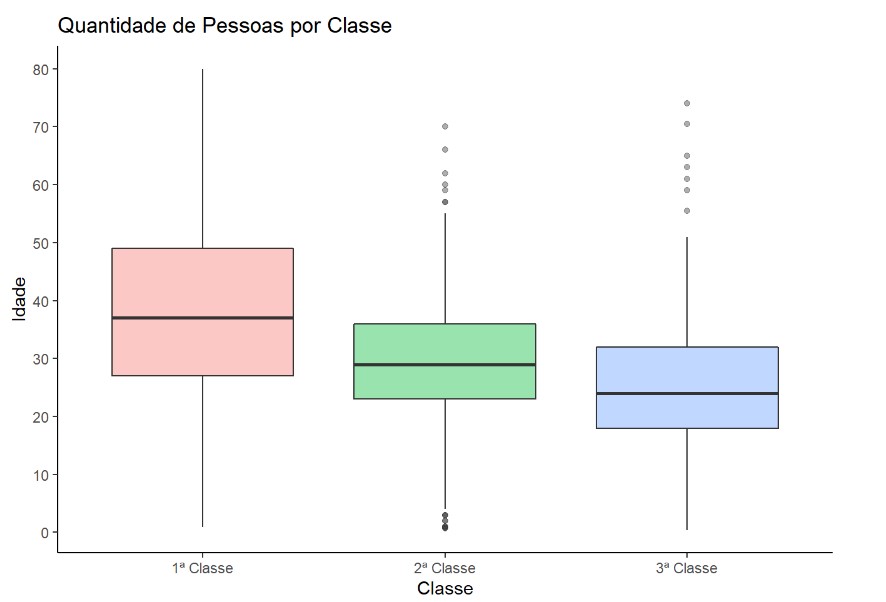
Podemos fazer um Group_by para visualizar o valor média por classe. Se você nuncaouviu falar em agrupamento, o artigo SQLDF, explica com maiores detalhes
df[complete.cases(df$Idade),] %>%
group_by(Classe) %>%
summarise(media = mean(Idade))
Podemos observar acima que a média da 1ª Classe é 38 anos, da 2ª Classe é 30 anos e da terceira Classe é 25 anos.

sapply(df, function(x) sum(is.na(x)))
Removemos os valores missing de idade. Na coluna "Embarque" temos 02 observações com nenhuma informação. Nesse caso, colocaremos nessa duas observações que está vazia, o valor “S”, pois representa 72 % do nosso conjunto de dados.
table <- rbind(table(df$Embarque),
paste0(round(prop.table(table(df$Embarque))*100, digit = 2),"%"))
rownames(table) <- c("Total","Percentual" )
table
O Titanic parou em três locais diferentes para que seus passegeiros pudessem embarcar: Cherbourg, Queenstown e Southampton, representados pelas letras C, Q e S no dataset, respectivamente.
df[c(62,830),9] <- "S"
df$Embarque <- factor(df$Embarque, labels = c(Cherbourg", "Queenstown","Southampton"))Na coluna Sovrevivente, colocaremos Naufragados no lugar de 0 e Sobrevivente no lugar de 1.
E na coluna Sexo no lugar, colocaremos Feminino e masculino para iniciarmos a análise exploratória de dados
df$Sobrevivente <- factor(df$Sobrevivente, labels = c("Naufragados","Sobrevivente"))
df$Sexo <- factor(df$Sexo, labels = c("Feminino", "Masculine"))my_fn <- function(data, mapping, ...){
p <- ggplot(data = data, mapping = mapping) +
geom_point(size = 2.48, colour = "#A9A9A9") +
geom_smooth(method=loess, fill = "red", color="red", ...)+
geom_smooth(method=lm, fill = "blue", color = "blue", ...)
p
}
# Gráfico ggpairs
ggpairs(df[,c(1,2,4:9)], lower = list(continuous = my_fn)) +
labs(title = "Correlação entre as variáveis")
Abaixo um gráfico de barra da quantidade de pessoas que sobreviveram ao naufrágio, e os que não sobreviveram.
ggplot(df, aes(Sobrevivente)) +
geom_bar(aes(fill = factor(Sobrevivente)), alpha = 0.5) +
theme_classic() +
labs(title = "Quantidade de Sobreviventes x Naufragados",
y = "Contagem",
fill = "Sobrevivente")
Gráfico de barra da quantidade de pessoas por gênero.
ggplot(df, aes(Sexo)) +
geom_bar(aes(fill = factor(Sexo)), alphe = 0.5) +
theme_classic() +
labs(title = "Quantidade de pessoas por Gênero",
y = "Contagem",
x = "Gênero",
fill = "")
Vamos usar a função prop.table() para visualizar a proporção de homens e mulheres.
prop.table(model_table) * 100| ## ## Feminino Masculino ## 35.2413 64.7587 |
Usaremos a função table() para visualizar a quantidade distinta de cada levels.
table(df$Sexo)| ## ## Feminino Masculino ## 314 577 |
Gráfico de barra da quantidade de pessoas por classe social.
ggplot(df, aes(Classe)) +
geom_bar(aes(fill = Classe), alpha = 0.5, show.legend = FALSE) +
theme_classic() +
labs(title = "Quantidade de Pessoas por Classe",
y = "Contagem",
x = "Classe",
fill = "Classe")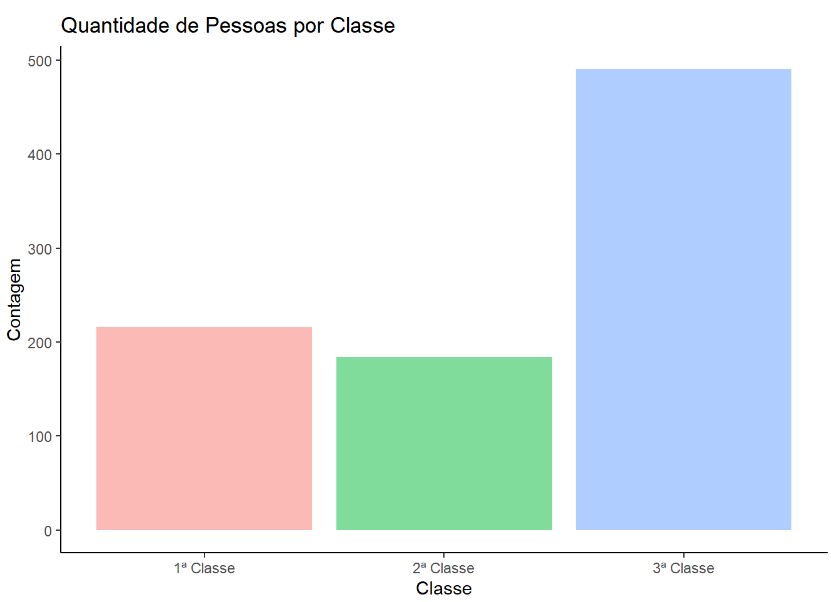
E abaixo um Gráfico de barra da quantidade de pessoas por sexo e por Embarcação.
ggplot(df) +
geom_bar(aes(y = Embarque, fill = Sexo, alphe = 0.5)) +
theme_classic() +
labs(title = "Quantidade de pessoas por Embarcação e Gênero",
y = "",
x = "Quantidade",
fill = "Sexo") +
theme(axis.text.y = element_text(angle = 45, hjust = 1))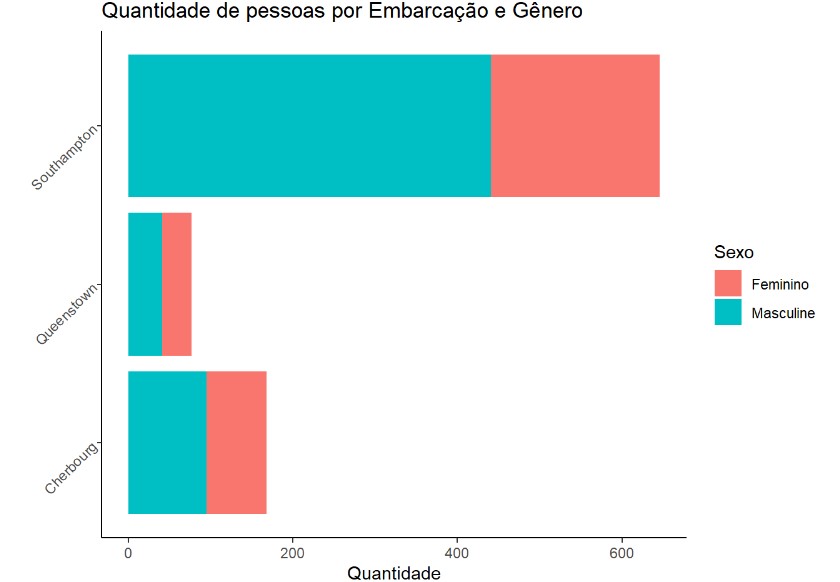
Criaremos um blox plot para ver qual a faixa etária dos sobreviventes e se a idade média das mulheres sobreviventes é maior do que a dos homens sobrevivente. Podemos observar que a média pelo gráfico das mulheres sobrevivente é muito próxima da idade dos homens sobreviventes. Para termos certeza se a média de idade dos gênero são iguais ou próxima teremos que realizar o teste de hipótese que será abordados nos próximos artigo.
subset(df,df$Sobrevivente == "Sobrevivente") %>%
ggplot(aes(Idade, Sexo)) +
geom_boxplot(aes(fill = as.factor(Sexo)), alpha = 0.4, show.legend = FALSE) +
theme_classic() +
labs(title = "BoxPlot dos Sobreviventes por Sexo x Idade",
y = "Sobrevivente",
x = "Idade") +
theme(axis.text.y = element_text(angle = 45, hjust = 1)) 
Já sabendo a média da faixa etária dos sobreviventes podemos fazer um outro gráfico, histograma, para conseguirmos visualizar quais as proporções por idade dos sobrevivente e a diferença entre mulher e home.
tmp_male <- subset(df, df$Sobrevivente == "Sobrevivente") %>% filter(Sexo=="Masculino", !is.na(Idade)) %>% select(Idade) %>% .[[1]]
b <- hist(tmp_male, 20, plot=FALSE)
tmp_female <- subset(df, df$Sobrevivente == "Sobrevivente") %>% filter(Sexo=="Feminino", !is.na(Idade)) %>% select(Idade) %>% .[[1]]
a <- hist(tmp_female, breaks = b$breaks, plot=FALSE)
df_density <- data.frame(Age=c(a$mids,b$mids),Density=c(a$density,b$density),Sex=c(rep("Feminino",length(a$mids)),rep("Maculino",length(b$mids))))
highchart() %>%
hc_xAxis(categories = df_density$Age) %>%
hc_add_series(name="Feminino", select(filter(df_density,Sex=="Feminino"),Density)[[1]], type="column", color='rgba(255, 192, 203, 0.30)', showInLegend=FALSE) %>%
hc_add_series(name="Masculine", select(filter(df_density,Sex=="Masculine"),Density)[[1]], type="column", color='rgba(68, 170, 255, 0.30)', showInLegend=FALSE) %>%
hc_add_series(name="Masculine", select(filter(df_density,Sex=="Masculine"),Density)[[1]], type="spline", color="#44AAFF") %>%
hc_add_series(name="Feminino", select(filter(df_density,Sex=="Feminino"),Density)[[1]], type="spline", color="#FFC0Cb") %>%
hc_tooltip(pointFormat = "{series.name}"
{point.y:.3f}",
shared = FALSE) %>%
hc_yAxis(title=list(text='Densidade')) %>%
hc_xAxis(title=list(text='Idade')) %>%
hc_title(text='Gráfico dos Sobreviventes por Idade')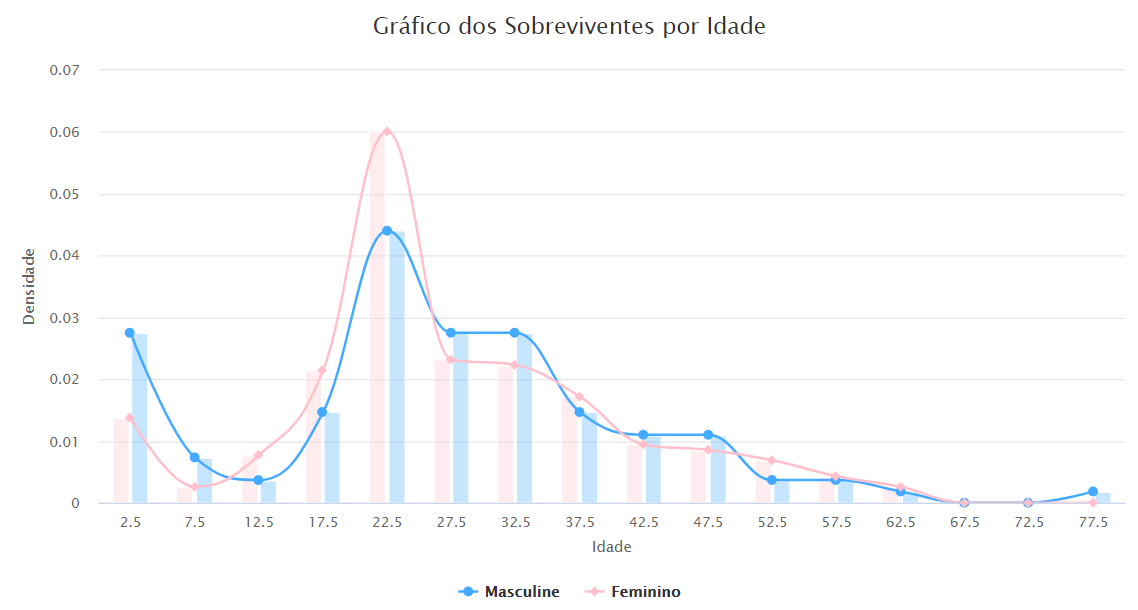
CrossTable(x = df$Sexo, y = df$Sobrevivente)
A função acima CrossTable() demonstra numericamente a relação entre o Sexo, e os sobreviventes
e naufragados, tabela cruzada . O nosso conjunto de dados, possui 891. sendo 314 mulheres, ou 35.20% e 577 homens ou 64.80%. A table
também mostre a quantidade de mulheres sobreviventes, 233 (74,2% do grupo de mulheres) e 81 mulheres naufragadas (25.80% do grupo de mulheres).
O mesmo análise temos na categoria dos homens, sendo 109 homens sobreviventes (18.90% do grupo de homens) e 468 homens
naufragados (81.10% do grupo de homens.
Abaixo temos também a quantidade de naufragados, 549 pessoas (61.60%) e de sobreviventes 342 pessoas (38.40%).Abaixo vamos mostrar mais um gráfico
em relação ao sexo, e sobrevivente e naufragados
female_rate <- nrow(df[df$Sexo == "Feminino" & df$Sobrevivente == "Sobrevivente",]) / nrow(df[df$Sexo == "Feminino",]) * 100
male_rate <- nrow(df[df$Sexo != "Feminino" & df$Sobrevivente == "Sobrevivente",]) / nrow(df[df$Sexo != "Feminino",]) * 100
ggplot(df, aes(Sexo)) +
geom_bar(aes(fill = Sexo, alpha = Sobrevivente), color="grey", show.legend = FALSE) +
labs(x = "Gênero",
y = "Quantidade",
title="Sobrevivente por Gênero") +
theme_bw(base_size = 18) +
scale_fill_manual(name="", values=c("E57373", "#42A5F5")) +
annotate("text", label=paste(round(female_rate,digits=3), "%"), x = 1, y = 250) +
annotate("text", label=paste(round(male_rate,digits=3), "%"), x = 2, y = 125)
Agora mostramos um gráfico separado por embarga, por títularidade do nome e é sobrevivente ou não.
df$Nome <- gsub('(.*, )|(\\..*)','', df$Nome)
df$Nome[df$Nome == 'Mlle']<- 'Miss'
df$Nome[df$Nome == 'Ms']<- 'Miss'
df$Nome[df$Nome == 'Mme']<- Mrs'
df$Nome[df$Nome == 'Lady']<- 'Miss'
df$Nome[df$Nome == 'Dona']<- 'Miss'
officer<- c('Capt','Col','Don','Dr','Jonkheer','Major','Rev','Sir','the Countess')
df$Nome[df$Nome %in% officer]<-'Officer'
df$Nome<- as.factor(df$Nome)
ggplot(data = df,aes(x=Nome,fill=df$Sobrevivente)) +
geom_bar(start = "identify") +
labs(y = "Quantidade",
fill = "Sobrevivente",
title = "Titularidade do Nome") +
scale_y_continuous(breaks = seq(min(0), max(400), by = 50)) +
facet_wrap(~Embarque) +
theme_test()
Para finalizarmos o nosso artigo deixaremos um gráfico abaixo, para que vocÊ possa refletir, pois será assunto para a próxima aula, regressão linear. No próximo artigo terá uma análise detalhada em relação a composição desse gráfico
ggplot(df, aes(x = df$`Irmãos/Cônjuge`, y = df$`Pais/Crianças`))+
geom_point() +
geom_smooth(method=loess, fill = "red", color="red")+
geom_smooth(method=lm, fill = "blue", color = "blue") +
theme_classic() +
labs(title = "Correção entre Irmãos / Cônjuge com Pais / Crianaças",
y = "Pais/Crianaças",
x = "Irmãos/Cônjuge")
Aprenda a trabalhar com duas ferramentas ao mesmo tempo, podemos trabalhar com SQL dentro do RStudio.

Um vetor em R é uma estrutura básica dentro da linguagem, que permite armazenar uma quantidade numérica ou string (letras ou caracteres), em um único objeto. O vetor possui apenas 01 única dimensão.

Matrizes é caracterizado como uma coleção de vetores, sendo todos do mesmo tipo (numérico ou caracteres) armazenados entre linhas e colunas.

Um data frame é semelhante a uma matriz mas as suas colunas têm nomes e podem conter dados de tipo diferente. Um data frame pode er visto como uma tabela de uma base de dados, em que cada linha corresponde a um registo (linha) da tabela.

Uma equação polinomial é caracterizada por ter um polinômio igual a zero. Ela pode ser caracterizada pelo grau do polinômio, e, quanto maior esse grau, maior será o grau de dificuldade para encontrar-se sua solução ou raiz.

Em Breve
 Nesse projete iremos analisar uma série temporal de uma empresa de locação de
bicicleta dos Estados. Unidos. O conjunto de dados é obtido na plataforma Kaggle. Nesse
conjunto de dados, iremos realizar uma análise exploratória em relação da demanda de locação
de bicicleta dos dias da semana, dia úteis, com dias de finais de semanas e feriados, qual a
correlação de locação de bicicleta com a temperatura e humidade do ar, se a velocidade do
vento interfere em relação a damanda de locação. Toda este projeto foi desenvolvido em
linguagem R.
Nesse projete iremos analisar uma série temporal de uma empresa de locação de
bicicleta dos Estados. Unidos. O conjunto de dados é obtido na plataforma Kaggle. Nesse
conjunto de dados, iremos realizar uma análise exploratória em relação da demanda de locação
de bicicleta dos dias da semana, dia úteis, com dias de finais de semanas e feriados, qual a
correlação de locação de bicicleta com a temperatura e humidade do ar, se a velocidade do
vento interfere em relação a damanda de locação. Toda este projeto foi desenvolvido em
linguagem R.


